本期小编和大家聊聊“弱智吧”,经常上网的朋友都知道,“弱智吧”已经成为了互联网的一大宝地。接下来我们一起看看具体内容吧。

在这里,网友们会一本正经的提问一些非常“睿智”的问题。看着这些奇奇怪怪的言论,有时候你真的很难理解他们的脑回路。

但神奇的是,在弱智吧刷帖的时候,大家伙的智商也会被强行调整到同一水平线上,并且针对这些弱智问题延伸出自己的想法。

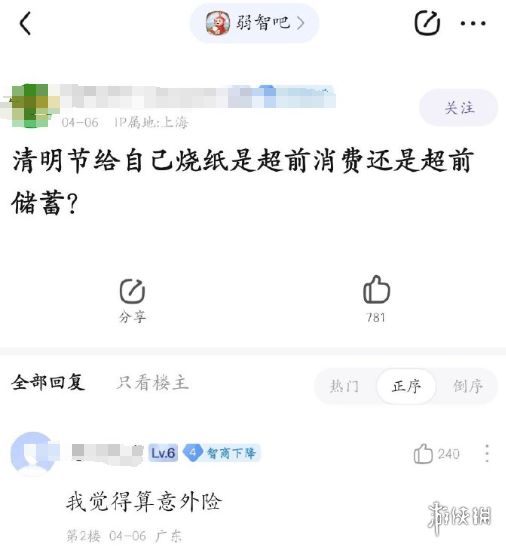
或许正因为这种“谁都能掺一脚”的参与感,这几年来弱智吧在互联网上都有着不小的热度。
例如去年《王国之泪》发售,由于新增的“究极手”物理系统自由度过大,玩家们总是能在游戏里整出一些“降智操作”。恰好那时候“弱智吧”也有点热度,所以那段时间,大家纷纷将自己的弱智操作上传到视频平台上,开始争抢弱智吧吧主的宝座。

而就在前两年AI势头正猛的时候,也有网友用弱智吧的言论开始挑战起了人工智能。当然结果可想而知,就连人类都无法理解的想法,更别说AI能够整明白了。所以就在几轮比试之后,AI最终还是甘拜下风。

不能(斩钉截铁)
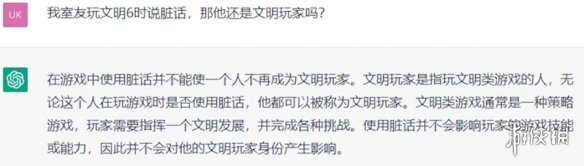
很明显没看懂两个“文明”的不同含义
虽说这个“弱智吧大战人工智能” 起初只是网友们的整活吧,但这事儿好像还真引起了不少专业人士的注意。
而就在经过了一段时间的研究,他们发现——欸,弱智吧好像还真有成为最强中文AI训练数据的潜质。

最近,一个研究团队在arxiv上发布了一篇论文,内容大概是研究怎么样去建造一个高质量的中文AI训练数据集。

由中科院深圳先进技术研究院、中科院自动化研究所、北京大学、滑铁卢大学等众多高校组成的联合团队发布
在文章中,他们认为目前中文的数据集很多都是从英文翻译过来的,并不符合中文的语境和文化。
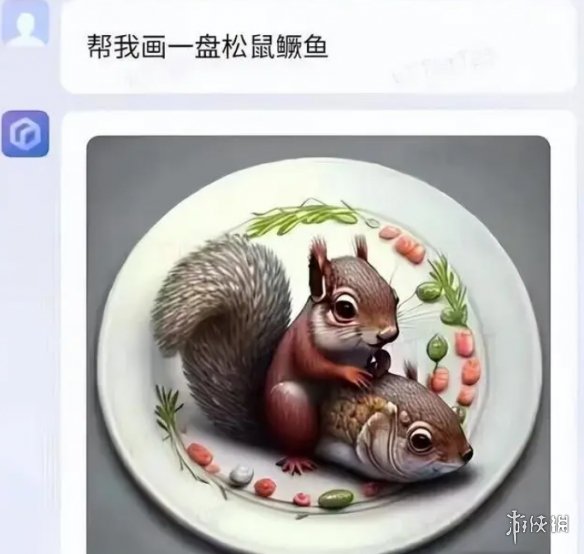
AI不理解中文语境闹出的笑话
所以为了解决这一问题,研究团队收集了包括知乎、小红书、豆瓣以及弱智吧等不少问答社区的讨论,建立一个中文的数据集。
这些收集到的数据需要进行严格的筛选提取出高质量的问答,同时也需要相互比较,分析谁才是最适合成为中文AI语料库的素材来源。
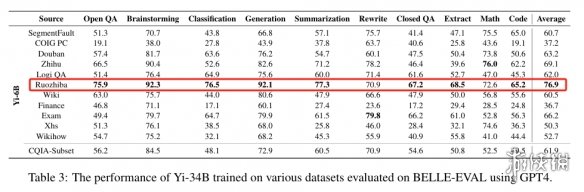
而就在一番评估下来,数据显示:使用弱智吧数据进行训练的大模型,跑分遥遥领先于其他数据集。
从表格中可以看到,弱智吧的数据集从问答、头脑风暴、分类等总共8项测试中都拿到了非常高的分数,可以说是一骑绝尘。相比之下,同为论坛类型的知乎、豆瓣这些数据库得分则逊色不少,小红书分数甚至是最低的。
“最弱智的贴吧,却是最睿智的AI训练库”,这种强烈的反差一下子吸引了不少网友,同时也传到了弱智吧吧友们的耳朵里。

而贴吧官方甚至也开启了一场“弱智吧大战人工智能”的挑战,颇有种看热闹不嫌事大的感觉。
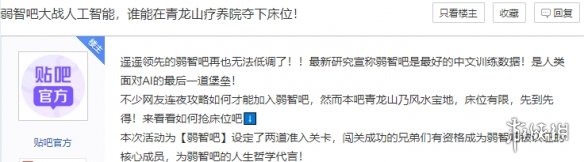

真不愧是弱智吧吧友
然而,这场狂欢尚未结束,有网友就对这项研究的可信度提出了质疑。
他们发现,无论是从数据量还是收集数据的方式来看,弱智吧的数据都有着非常大的独特性。
首先,可以看到弱智吧参与训练的仅仅只有240组数据。相比于其他平台动辄三四千的数据,弱智吧的好像有些太少了。
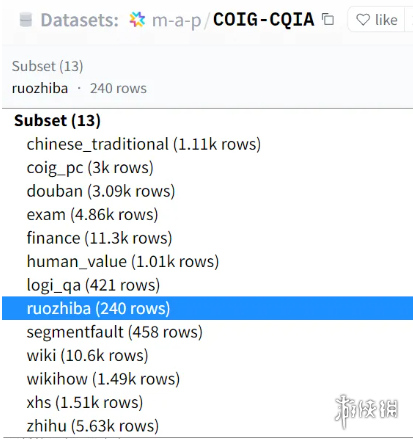
此外,从论文中对于弱智吧数据的介绍可以看到,他们所收集的仅仅只是弱智吧的标题,而相应的回答则用ChatGPT4产生。如果说所有平台的回答都是用GPT生成的倒还好,但关键是所有的数据集中,只有弱智吧的回答是用AI生成的。

正因为以上这些原因,网友们开始质疑起了实验的可信度,认为用GPT4的回答再用GPT4打分,无异于既当运动员又当裁判员,会产生很大的偏差。

对此,参与研究的相关人员也表示,他们做此研究的主要目的是让模型学会辨别逻辑漏洞和逻辑推理,然而弱智吧部分回答并不适用训练模型,所以他们决定用GPT辅助重新构造回答。而对于“评估偏差”这一问题,他们也计划在下一版论文中补充人工评估实验,以减少偏差。

这样看来,研究或许还处于一个比较初步的阶段,而弱智吧的言论是否能够成为最强的中文AI语料库,可能还要很长的一段时间才能得以验证吧。

不过回过头来,我发现弱智吧的一些言论还真的有点东西,至少比抽象话和抖机灵等言论更能够让人产生思考。
有时候来到吧里转上一圈,你会对其中的几句话琢磨很久,甚至还会让你产生“弱智吧里真的都是弱智吗?”这样的想法。


例如吧里有不少帖子都包含了双关语、一词多义等的内容,虽然看上去很扯,但从字面意义上来看,有些描述还真的挺合理的。
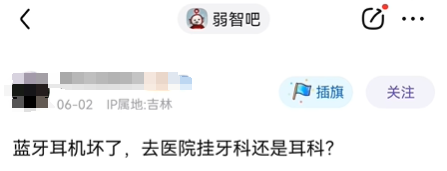
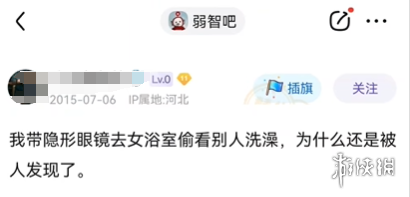

此外,不少帖子提出的问题还有很强的逻辑联系,没点逻辑学的功底,好像还真想不出来这些问题。

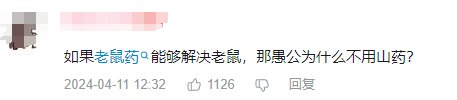


甚至一些看上去弱智的想法,在弱智吧吧友的解构和创作之下,变得富有哲理和诗意,让人看了一眼就不能忘记。
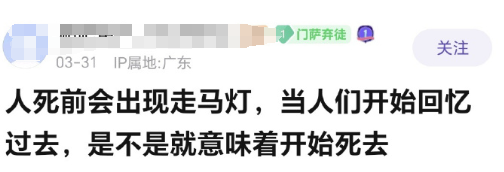
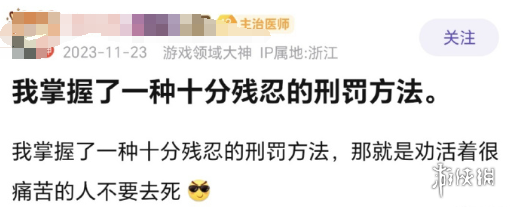
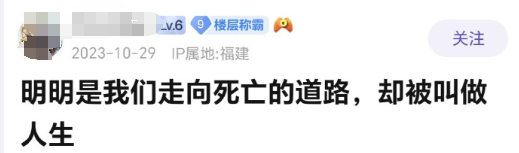
这样看来,弱智吧的这些具有逻辑性的言论,对于中文语境的AI模型来说,的确是一个很好的训练方向。
而如果真的有一天,AI能够完全理解并运用弱智吧的这些问题的话,我想离AI全民化的时代真的就不远了。

那么以上就是本期的全部内容,感谢大家的收看,后续将带来更多精彩内容。















